原文:Do we think of git commits as diffs, snapshots, and/or histories?
首发:Git 提交是差异、快照还是历史记录? @Linux 中国
首发时间:2024-01-21 18:47 (UTC+8)
作者:Pratham Patel
译者:LCTT Cubik
Git 提交是差异、快照还是历史记录?

大家好!我一直在慢慢摸索如何解释 Git 中的各个核心理念(提交、分支、远程、暂存区),而提交这个概念却出奇地棘手。
要明白 Git 提交是如何实现的对我来说相当简单(这些都是确定的!我可以直接查看!),但是要弄清楚别人是怎么看待提交的却相当困难。所以,就像我最近一直在做的那样,我在 Mastodon 上问了一些问题。
大家是怎么看待 Git 提交的?
我进行了一个 非常不科学的调查,询问大家是怎么看待 Git 提交的:是快照、差异,还是所有之前提交的列表?(当然,把它看作这三者都是合理的,但我很好奇人们的 主要 观点)。这是调查结果:
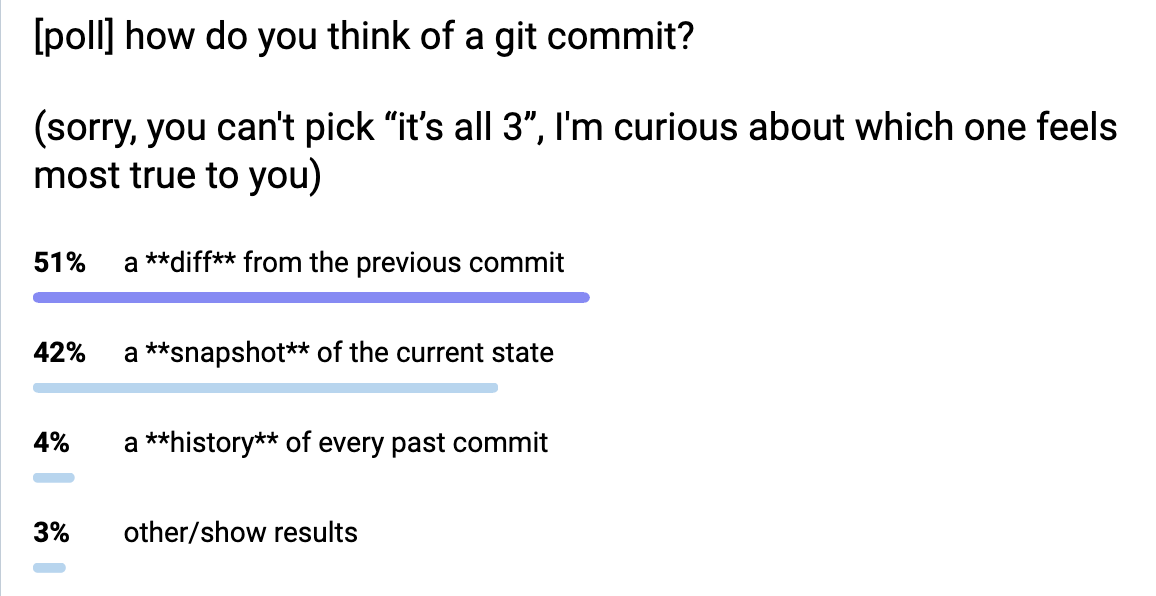
结果是:
- 51% 差异
- 42% 快照
- 4% 所有之前的提交的历史记录
- 3% “其他”
我很惊讶差异和快照两个选项的比例如此接近。人们还提出了一些有趣但相互矛盾的观点,比如 “在我看来,提交是一个差异,但我认为它实际上是以快照的形式实现的” 和 “在我看来,提交是一个快照,但我认为它实际上是以差异的形式实现的”。关于提交的实际实现方式,我们稍后再详谈。
在我们进一步讨论之前:我们的说 “一个差异” 或 “一个快照” 都是什么意思?
什么是差异?
我说的“差异”可能相当明显:差异就是你在运行 git show COMMIT_ID 时得到的东西。例如,这是一个 rbspy 项目中的拼写错误修复:
1 | diff --git a/src/ui/summary.rs b/src/ui/summary.rs |
你可以在 GitHub 上看到它: https://github.com/rbspy/rbspy/commit/24ad81d2439f9e63dd91cc1126ca1bb5d3a4da5b
什么是快照?
我说的 “快照” 是指 “当你运行 git checkout COMMIT_ID 时得到的所有文件”。
Git 通常将提交的文件列表称为 “树”(如“目录树”),你可以在 GitHub 上看到上述提交的所有文件:
https://github.com/rbspy/rbspy/tree/24ad81d2439f9e63dd91cc1126ca1bb5d3a4da5b(它是 /tree/ 而不是 /commit/)
“Git 是如何实现的”真的是正确的解释方式吗?
我最常听到的关于学习 Git 的建议大概是 “只要学会 Git 在内部是如何表示事物的,一切都会变得清晰明了”。我显然非常喜欢这种观点(如果你花了一些时间阅读这个博客,你就会知道我 喜欢 思考事物在内部是如何实现的)。
但是作为一个学习 Git 的方法,它并没有我希望的那么成功!通常我会兴奋地开始解释 “好的,所以 Git 提交是一个快照,它有一个指向它的父提交的指针,然后一个分支是一个指向提交的指针,然后……”,但是我试图帮助的人会告诉我,他们并没有真正发现这个解释有多有用,他们仍然不明白。所以我一直在考虑其他方案。
但是让我们还是先谈谈内部实现吧。
Git 是如何在内部表示提交的 —— 快照
在内部,Git 将提交表示为快照(它存储每个文件当前版本的 “树”)。我在 在一个 Git 仓库中,你的文件在哪里? 中写过这个,但下面是一个非常快速的内部格式概述。
这是一个提交的表示方式:
1 | git cat-file -p 24ad81d2439f9e63dd91cc1126ca1bb5d3a4da5b |
以及,当我们查看这个树对象时,我们会看到这个提交中仓库根目录下每个文件/子目录的列表:
1 | git cat-file -p e197a79bef523842c91ee06fa19a51446975ec35 |
这意味着检出一个 Git 提交总是很快的:对 Git 来说,检出昨天的提交和检出 100 万个提交之前的提交一样容易。Git 永远不需要重新应用 10000 个差异来确定当前状态,因为提交根本就不是以差异的形式存储的。
快照使用 packfile 进行压缩
我刚刚提到了 Git 提交是一个快照,但是,当有人说 “在我看来,提交是一个快照,但我认为它在实现上是一个差异” 时,这其实也是对的!Git 提交并不是以你可能习惯的差异的形式表示的(它们不是以与上一个提交的差异的形式存储在磁盘上的),但基本的直觉是,如果你要对一个 10,000 行的文件编辑 500 次,那么存储 500 份文件的效率会很低。
Git 有一个将文件以差异的形式存储的方法。这被称为 “packfile”,Git 会定期进行垃圾回收,将你的数据压缩成 packfile 以节省磁盘空间。当你 git clone 一个仓库时,Git 也会压缩数据。
这里,我没有足够的篇幅来完整地解释 packfile 是如何工作的(Aditya Mukerjee 的 《解压 Git packfile》是我最喜欢的解释它们是如何工作的文章)。不过,我可以在这里简单总结一下我对 deltas 工作原理的理解,以及它们与 diff 的区别:
- 对象存储为 “原始文件” 和一个 “变化量” 的引用
- 变化量是一系列例如 “读取第 0 到 100 字节,然后插入字节 ‘hello there’,然后读取第 120 到 200 字节” 的指令。它从原始文件中拼凑出新的文本。所以没有 “删除” 的概念,只有复制和添加。
- 我认为变化量的层次较少:我不知道如何检查 Git 究竟要经过多少层变化量才能得到一个给定的对象,但我的印象是通常不会很多。可能少于 10 层?不过,我很想知道如何才能真正查出来。
- 原始文件不一定来自上一个提交,它可以是任何东西。也许它甚至可以来自一个更晚的提交?我不确定。
- 没有一个 “正确的” 算法来计算变化量,Git 只是有一些近似的启发式算法
当你查看差异时,实际上发生了一些奇怪的事情
当我们运行 git show SOME_COMMIT 来查看某个提交的差异时,实际上发生的事情有点反直觉。我的理解是:
- Git 会在 packfile 中查找并应用变化量来重建该提交和其父提交的树。
- Git 会对两个目录树(当前提交的目录树和父提交的目录树)进行差异比较。通常这很快,因为几乎所有的文件都是完全一样的,所以 git 只需比较相同文件的哈希值就可以了,几乎所有时候都不用做什么。
- 最后 Git 会展示差异
所以,Git 会将变化量转换为快照,然后计算差异。它感觉有点奇怪,因为它从一个类似差异的东西开始,最终得到另一个类似差异的东西,但是变化量和差异实际上是完全不同的,所以这是说得通的。
也就是说,我认为 Git 将提交存储为快照,而 packfile 只是一个实现细节,目的是节省磁盘空间并加快克隆速度。我其实从来没必要知道 packfile 是如何工作的,但它确实能帮助我理解 Git 是如何在不占用太多磁盘空间的情况下将提交快照化的。
一个 “错误的” Git 理解:提交是差异
我认为一个相当常见的,对 Git 的 “错误” 的理解是:
- 提交是以基于上一个提交的差异的形式存储的(加上指向父提交的指针和作者和消息)。
- 要获取提交的当前状态,Git 需要从头开始重新应用所有之前的提交。
这个理解当然是错误的(在现实中,提交是以快照的形式存储的,差异是从这些快照计算出来的),但是对我来说它似乎非常有用而且有意义!在考虑合并提交时会有一点奇怪,但是或许我们可以说这只是基于合并提交的第一个父提交的差异。
我认为这个错误的理解有的时候非常有用,而且对于日常 Git 使用来说它似乎并没有什么问题。我真的很喜欢它将我们最常使用的东西(差异)作为最基本的元素——它对我来说非常直观。
我也一直在思考一些其他有用但 “错误” 的 Git 理解,比如:
- 提交信息可以被编辑(实际上不能,你只是复制了一个相同的提交然后给了它一个新的信息,旧的提交仍然存在)
- 提交可以被移动到一个不同的基础上(类似地,它们是被复制了)
我认为有一系列非常有意义的、 “错误” 的对 Git 的理解,它们在很大程度上都受到 Git 用户界面的支持,并且在大多数情况下都不会产生什么问题。但是当你想要撤销一个更改或者出现问题时,它可能会变得混乱。
将提交视为差异的一些优势
就算我知道在 Git 中提交是快照,我可能大部分时间也都将它们视为差异,因为:
- 大多时候我都在关注我正在做的 更改 —— 如果我只是改变了一行代码,显然我主要是在考虑那一行代码而不是整个代码库的当前状态
- 点击 GitHub 上的 Git 提交或者使用
git show时,你会看到差异,所以这只是我习惯看到的东西 - 我经常使用变基,它就是关于重新应用差异的
将提交视为快照的一些优势
但是我有时也会将提交视为快照,因为:
- Git 经常对文件的移动感到困惑:有时我移动了一个文件并编辑了它,Git 无法识别它是否被移动过,而是显示为 “删除了 old.py,添加了 new.py”。这是因为 Git 只存储快照,所以当它显示 “移动 old.py -> new.py” 时,只是猜测,因为 old.py 和 new.py 的内容相似。
- 这种方式更容易理解
git checkout COMMIT_ID在做什么(重新应用 10000 个提交的想法让我感到很有压力) - 合并提交在我看来更像是快照,因为合并的提交实际上可以是任何东西(它只是一个新的快照!)。它帮助我理解为什么在解决合并冲突时可以进行任意更改,以及为什么在解决冲突时要小心。
其他一些关于提交的理解
Mastodon 的一些回复中还提到了:
- 有关提交的 “额外的” 带外信息,比如电子邮件、GitHub 拉取请求或者你和同事的对话
- 将“差异”视为一个“之前的状态 + 之后的状态”
- 以及,当然,很多人根据情况的不同以不同的方式看待提交
人们在谈论提交时使用的其他一些词可能不那么含糊:
- “修订”(似乎更像是快照)
- “补丁”(看起来更像是差异)
就到这里吧!
我很难了解人们对 Git 有哪些不同的理解。尤其棘手的是,尽管 “错误” 的理解往往非常有用,但人们却非常热衷于警惕 “错误” 的心智模式,所以人们不愿意分享他们 “错误” 的想法,生怕有什么 Git 解释者会站出来向他们解释为什么他们是错的。(这些 Git 解释者通常是出于善意的,但是无论如何它都会产生一种负面影响)
但是我学到了很多!我仍然不完全清楚该如何谈论提交,但是我们最终会弄清楚的。
感谢 Marco Rogers、Marie Flanagan 以及 Mastodon 上的所有人和我讨论 Git 提交。
(题图:DA/cc0cada9-4945-4248-8635-3f89dcebd6ef)
via: https://jvns.ca/blog/2024/01/05/do-we-think-of-git-commits-as-diffs--snapshots--or-histories/
作者:Julia Evans
选题:lujun9972
译者:Cubik65536
校对:wxy
本文采用 署名 - 相同方式共享 4.0 国际 许可协议,转载请注明出处。

